How Nvidia assesses SuperPOD AI storage performance – Blocks ...
Nvidia’s GPUDirect tech has led to a focus on storage array bandwidth, however its SuperPOD certification emphasizes bandwidth, latency, scalability, and large dataset handling.

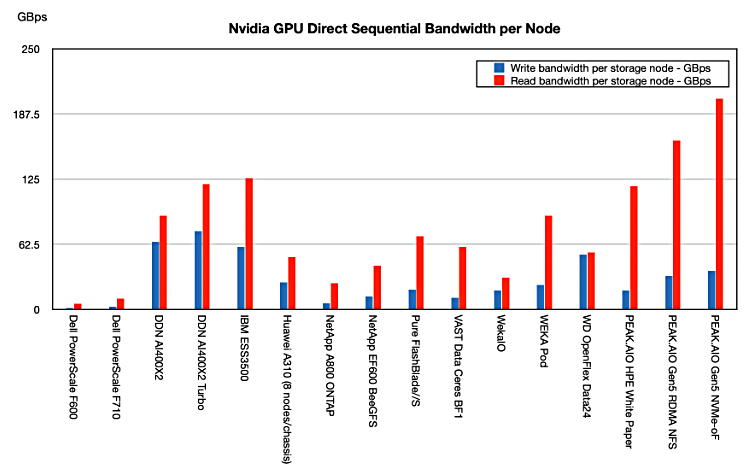
GPUDirect Storage (GDS) was devised to bypass a storage server/array controller’s host OS and CPU/memory by using direct IO to NVMe storage drives, thus speeding read and write access. Vendors publicized their GDS performance, thus providing a way to compare them:
We collated results from ten suppliers over the last coupler of years, as the chart above indicates. The AI market is maturing with a divide between training and inference workloads, the addition of RAG and vector search, and the notion of an AI data pipeline. Storage for today’s AI has to support all the stages of that pipeline and, hopefully, meet the needs of both inference and training data access.
With that in mind, Nvidia’s DGX SuperPOD, its largest GPU server, has certified storage suppliers that have to do more than ship data at high speed to GPUs. Bandwidth, although important, is no longer enough. As we understand it, attempting to define a per-node-level GPUDirect performance is the wrong approach. The approach should be more holistic: can you provide a level of performance to keep a SuperPOD busy and meet Nvidia’s latency criteria, sustained performance levels, scalability to support thousands of GPUs, large AI dataset handling, system and software compatibility requirements?
Performance is highly important, but not just GDS bandwidth. Scalability is crucial too. Hari Kannan, a senior director at Pure Storage, told B&F: “We’re moving forward with Nvidia SuperPOD certification, which is very much around performance. That’s what SuperPOD is all about. It guarantees that level of performance at a very high scale. And we’ve had to share our performance benchmarks with Nvidia for that. They’ve done their own testing to validate that it’ll meet all their SuperPOD benchmarks.” These benchmarks are not public.
There are four known certified SuperPOD storage suppliers: DDN and its A³I A1400X2T Lustre array, IBM with Storage Scale System 6000, NetApp with EF600 running BeeGFS, and VAST Data with its Data Platform. All four provide parallel file system access.
Storage suppliers with planned SuperPOD support include Dell with PowerScale, Pure Storage, and WEKA with WEKApod.

Dell is adding parallel file system support to its PowerScale OneFS operating system in Project Lightning. This may well help it meet SuperPOD performance and scalability requirements.
We understand that Hitachi Vantara, which already has BasePOD certification for its VSP One storage, will be pursuing SuperPOD certification as well. We have asked if NetApp’s ONTAP AFF arrays will be SuperPOD-certified, and will update this story if we hear back.
MinIO says its open source DataPOD object storage can scale out to support any number of GPU servers, but we understand it is not pursuing SuperPOD certification. That certification is for file system storage. There may be object storage behind it, but the upfront presentation is a file system.
SuperPOD storage certification is much more of a yes/no compatibility test than a how-fast-can-you-go benchmark result. Nvidia’s market interest is best served by having a number of storage suppliers certified for SuperPOD data access, and not by having a public SuperPOD performance benchmark that prospects can examine to find the fastest storage supplier. We don’t expect suppliers’ storage performance numbers for SuperPOD to be made public.







































